Dictionaries and tolerant retrival
Hashtables
- Each vocalulary term is hashed to an integer.
- Procs : Lookup is faster than a tree => O(1)
- Cons : No easy way to find minor variants
No prefix search
if vocalbulary keeps growing, need to occasionally do the expensive operaiton of rehashing everything.
Waste memory space
In the worst case, it performs terribly
Irregular search time
Trees
- Simplest Binary tree
- More usual : B+ tree
- Trees require a standard ordering of characters and hence strings … but, we typically have one
- Pros : Solves the prefix problem (ex. terms starting with hany)
Optimized for disk-based retrieval - Cons : Slower => O(logM) ( this requires balanced tree ) / Rebalancing binary trees is expensive
B+ tree
- Indexing mechanisms used to speed up access to desired data.
- Search Key : attribute to set of attributes used to look up records in a file
- Index file : consists of records ( called index entries ) of them
- TWO basic kind of indices :
- Ordered Indices : search keys are stored in sorted order
- Hash indices : search keys are distributed uniformly across “bucket” using a “hash function”
Index Evaluataion Metrics
- Access types supported efficiently
- Access time
- Insertion time
- Deletion time
- Space overhead
Ordered Indics
- In an Ordered Index, Index entries are stored sorted on the search key value
- Primary Index (Clustering index): in sequentially ordered fiel, this index whose search key specifies the sequential order of the file.
- Secondary Index (“non-clustering index”): ans index whose search by key specfiies an order diffent from the sequential of the file.
Dense_Index_Files
Dens-Index - Index record appears for every search-key value in the file.
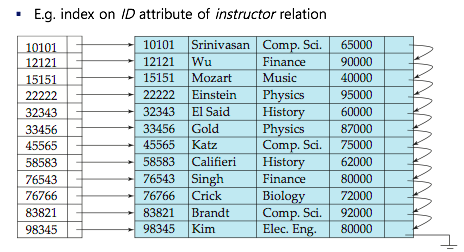
- Dense index on dept_name, with instructor file sorted on dept_name
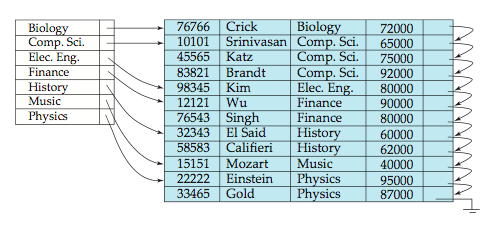
Sparse_Index_Files
- contatins index records for only some search-key values
- To locate a record with search key value k we
Find index record with search-key value K we
Search file sequentially starting at the reocord to which the index record points
Secondary Indics
- Indexed record points to a buket that contains pointer
to all the actual records with that particular search-key value - Secondary indics hav to be dense
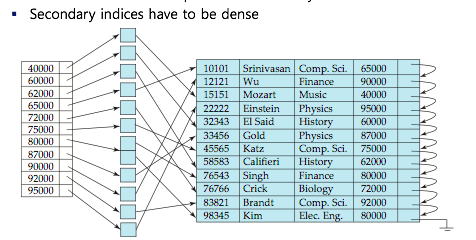
Primary and Secondary Indics
- Indices offer substantial benefits when searching for records
- BUT: Updating indices imposes overhead on database modification when a file is modifided, every index on the file must be updated.
- Sequential scan using primary index is efficient, but a sequential scan using a secondary index is expensive
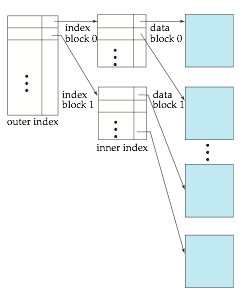
Multilevel Index
- If primary index does not fit in memory, access becomes expensive
- Solution: treat primary index kept on disk as a sequential file and construct a sparse index on it.
- outer index – a sparse index of primary index
- inner index – the primary index file
- If even outer index is too large to fit in main memory, yet another level of index can be created, and so on
- Indices at all levels must be updated on insertion or deletion from the file.
B+-Tree Index Files
B+-tree is a rooted tree satisfying the following properties:
- All paths from root to leaf are of the same length (balanced)
==> Complete Binary Rebalanceing Tree - Each node that is not a root or a leaf has between [n/2] and n children
- A leaf node has between [(n−1)/2] and n–1 values
- Special cases:
1.If the root is not a leaf, it has at least 2 children.
2.If the root is a leaf (that is, there are no other nodes in the tree), it can have between 0 and (n–1) values.
Disk-base data structure (not main memory)
- Page
Fanout n of a node: the number of pointers out of the node