Boolean Model
- Strength
- Rich expressions for queries
- Clear logical interpretation
- Problems
- Relevancy ( = Score , two component [ query, document ] ) is either 1 or 0
many documents or few/no documents in the result
No term weighting in document and query is used - Difficulty for end-users for form a correct Boolean query
- Problem with Boolean search
- Boolean queries often result in either too few (=0) or too many (1000s) results
Example)
Query 1: “standard user iptime N4” → 200,000 hits
Query 2: “standard user iptime N4 no channel found” → 0 hits - It takes a lot of skill to come up with a query that produces a manageable number of hits
( AND gives too few; OR gives too many )
- Boolean queries often result in either too few (=0) or too many (1000s) results
–> Solution : Ranked Retrieval
Ranked retrieval
Using Free Text Queries
- Feast or famine: not a problem in ranked retrieval
- Query Document Matching Scores
( 해당 term 이 많이 있으면 High Score 부여 - Jaccard coefficient )
Jaccard coefficient
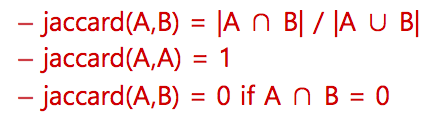
- A and B don’t have to be the same size
- Always assings a nubmer between 0 and 1
Example)
Query : idess of march
Doc1 : caesar died in march → jaccard : 1/6
Doc2 : the long march → jaccard : 1/5
→ 의미상으론 Doc1 이 더 가깝지만 jaccard 를 통해 Doc2 가 더 높은 rank 를 부여받는다.
- We need a more sophisticated way of normalizing for length
Bag of words model
- Term Frequency
- don’t consider ordering of words
- Term Frequency : tf
- The term frequency tf(t,d) of term t in document d is defined as the number of times that t occurs in d.
Log-frequency weighting

Example)
Doc1 : Hanyang Ansan Univ Hanyang
Query : Hanyang Ansan
→ score(query,doc1) = (1 + log(2)) : Hanyang 2번 + (1 + log(0)) : Ansan 0번 = 2
- Document frequency
-
Rare terms are more informative than frequent terms
→ We want a high weight for rare terms like arachnocentric.8 -
Document frequency : df
idf weight

Effect of idf on ranking
- idf has no effect on ranking one term queries
( if one term, same ranking with df ) - idf affects the ranking of documents for queries with at least two terms
tf-idf weighting

Score for a document given a query
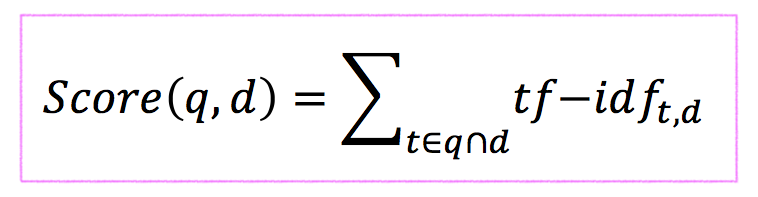
Example)
Query : Hanyang Univ
Doc1 : Hanyang Ansan Univ Hanyang
Doc2 : Hanyang Ansan
→ score(query, doc1) = [ ( 1 + log(2) ) x log (10/2) ] : Hanyang + [ 1 x log(10/1) ] : Univ
→ score(query, doc2) = [ (1) x log(10/1) ] : Hanyang